

Spis treści
„Duplicate content” to po polsku po prostu „powielona treść”. Ale jakiego powielenia to dotyczy? W jaki sposób wpływa na pozycjonowanie strony i jej ocenę przez Google? Aby odpowiedzieć na to pytanie, musimy najpierw uściślić, co pojęcie to dokładnie oznacza. Pozwoli to lepiej zrozumieć, jaki wpływ ma zjawisko duplikacji treści na pozycjonowanie danej witryny. A wiedza na ten temat jest niezwykle istotna – zwłaszcza jeśli chcesz, aby Twoja strona znajdowała się na jak najlepszych miejscach na liście wyników wyszukiwania.
Czym jest duplicate content?
Duplicate content to po prostu ten sam tekst znajdujący się na kilku stronach, czyli pod różnymi adresami URL. Może znajdować się na jednej lub wielu domenach. W pierwszej sytuacji jest to wewnętrzny duplicate content, w drugiej – zewnętrzny duplicate content.
Zewnętrzny duplicate content
Powtarzane treści możemy odnaleźć na co dzień w wielu domenach – wiele serwisów internetowych przedrukowuje artykuły lub newsy od swoich partnerów, pojawiają się na nich także takie same informacje prasowe, pochodzące z jednego źródła. W przypadku przedruków warto zauważyć, że zawsze pod spodem podane jest źródło pochodzenia danego tekstu. Jeśli nie ma tam źródła, a tekst pochodzi z innej witryny, mamy w świetle prawa do czynienia po prostu z kradzieżą – o czym należy pamiętać, jeśli chcesz umieścić u siebie tekst od kogoś innego.
Link jest nie tylko sposobem na to, aby wskazać oryginalne pochodzenie treści. Dla twórcy oryginalnego wpisu jest także jedną z metod pomagających w pozycjonowaniu strony. Nie należy bowiem zapominać, że to, ile witryn do niej linkuje, znacznie wpływa na jej miejsce w wyszukiwarce. Strony przedrukowujące teksty muszą pamiętać, że Google promuje źródło, a więc w wynikach będzie ukazywać witrynę oryginalną, zaś te adresy, które mają treść przedrukowaną, są pomijane. Aby nie było zamieszania, często korzysta się z metatagu „canonical”, który wskazuje robotom miejsce źródłowe, gdzie po raz pierwszy pojawia się dana treść.
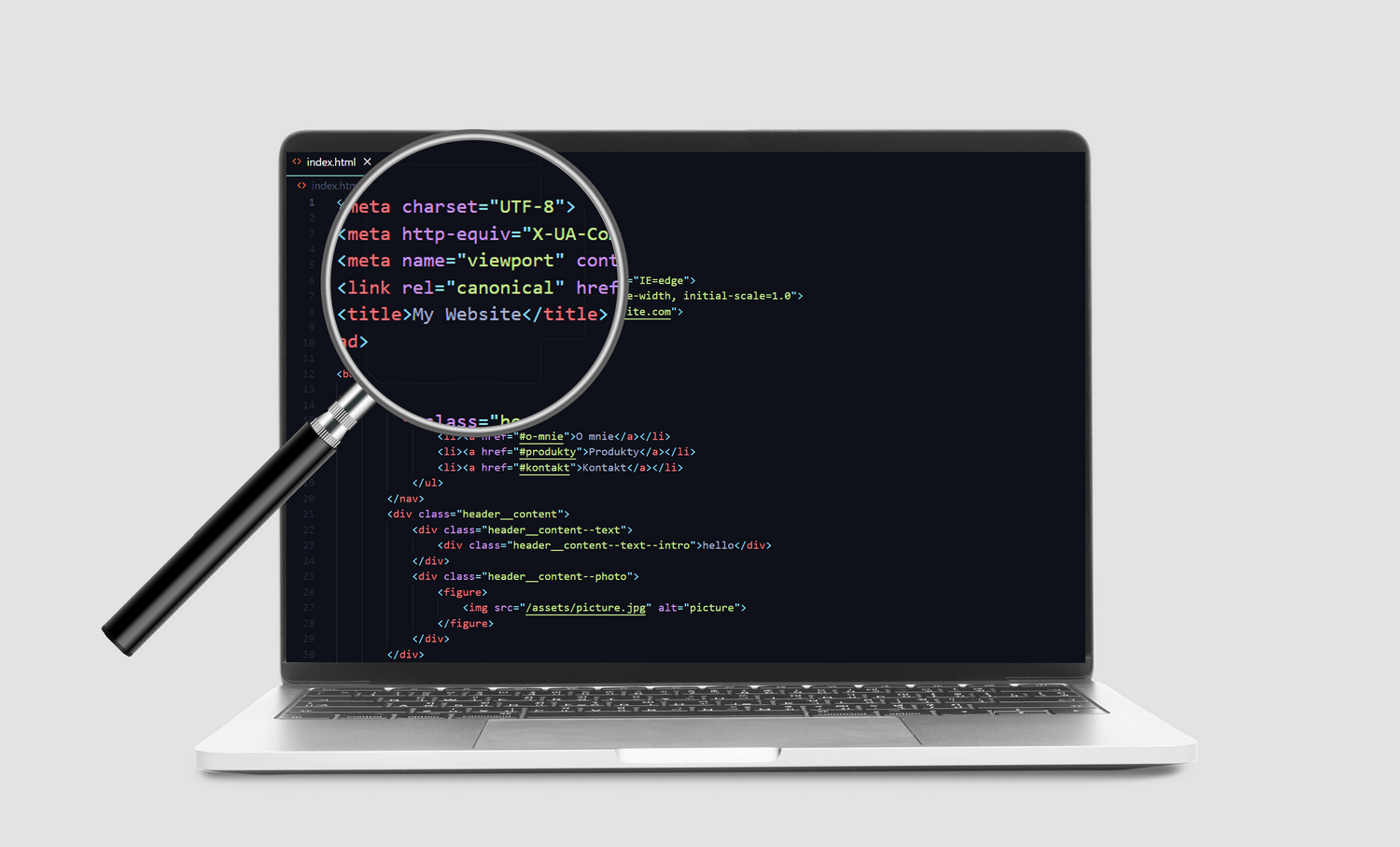
Umieszczanie w kodzie strony matatagu „canonical”.
Wewnętrzny duplicate content
Jeśli chodzi o duplicate content w ramach jednej witryny, w takiej sytuacji oznacza to, że właściciel strony zamieścił te same treści na kilku podstronach. Doskonałym przykładem mogą być sklepy internetowe, które posiadają jeden produkt w kilku wersjach kolorystycznych. Jak można często zauważyć, w takiej sytuacji właściciele „idą na łatwiznę” i zamieszczają taki sam opis dla każdego, dodając tylko do nazwy produktu nazwę koloru lub zmieniając ją, np. „miękki dywan ABC123 w kolorze czerwonym” i „miękki dywan ABC123 w kolorze granatowym”. Aby dla robotów Google treść była oryginalna, każdy opis musi być przynajmniej w 40% odmienny od pozostałych.

Brzmi ciekawie?
Umów bezpłatną konsultacjęJak uniknąć powielania treści?
Powielanie treści jest – niestety – powszechne, ponieważ istnieje szereg błędów, które, mniej lub bardziej świadomie, popełniają twórcy i administratorzy stron. W przypadku zewnętrznego duplicate content jest to:
- brak wspomnianego wyżej metatagu „canonical”, który określa źródło treści;
- zła konfiguracja domeny – jeśli domena źródłowa nie jest właściwie skonfigurowana, a treść zostanie powielona w innej domenie, wówczas roboty Google wybiorą tylko jedną, która będzie się wyświetlać w wynikach wyszukiwania, i może nie być to ta, na której tekst pojawił się po raz pierwszy.
Jak podaje zresztą samo Google:
Jeśli rozpowszechniasz treści również w innych witrynach, Google zawsze pokaże tę wersję, która zdaniem wyszukiwarki będzie najlepiej pasowała do zapytania użytkownika. Może, ale nie musi to być wersja, którą chcesz pokazać. W takiej sytuacji pomaga zamieszczenie w każdej witrynie, w której są rozpowszechniane Twoje treści, linku do oryginalnej wersji danego artykułu. Możesz też poprosić webmasterów korzystających z rozpowszechnianych przez Ciebie materiałów, aby użyli metatagu noindex, dzięki czemu wyszukiwarki nie będą mogły indeksować tej wersji treści, która znajduje się w ich witrynach […].
Jeśli chodzi o wewnętrzny duplicate content, tutaj najczęściej spotykane błędy to:
- stosowanie identyfikatorów sesji – jeśli stosujesz trackery lub rozwiązania pozwalające na identyfikowanie sesji użytkownika, wówczas identyfikator trafia do adresu strony, tworząc w ten sposób nowy adres URL;
- brak przekierowania 301 – jeśli adres podstrony zostanie zmieniony lub zostanie ona usunięta, przekierowanie 301 umożliwia zachowanie zdobytej pozycji oraz przeniesienie jej na nową podstronę, do której następuje przekierowanie. Dzięki temu nie tracisz efektów swojej pracy;
- wersja do druku – dotyczy to głównie stron mających artykuły oraz udostępniających je do druku. Jeśli istnieje wersja do pobrania (na przykład w formie pliku PDF) i nie zostanie oznaczona tagiem noindex, będzie traktowana jako duplikat i nie wiadomo, którą w wynikach będzie wskazywać Google;
- błąd w adresie – jeśli adres URL zawiera dodatkowe parametry, wówczas jest on traktowany jako osobny, a przez to automatycznie każda treść na nim oceniana jest jako zduplikowana. Przykład – masz stronę z butami, gdzie pod produktami znajduje się ogólny opis trendów obuwniczych na bieżący rok. Jeśli jest tam filtr pozwalający na ułożenie butów według ustalonych parametrów, po jego użyciu strona zostanie przez roboty Google zapamiętana, a ponieważ opis pod spodem pozostanie bez zmian, dojdzie do duplikacji treści.
Jak wykryć powielone treści?
Skąd jednak wiedzieć, że treści się powielają? To wymaga osobnego omówienia, jednak najprostszym sposobem na to, aby to sprawdzić, jest po prostu wklejenie dwóch–trzech zdań treści do wyszukiwarki Google i sprawdzenie wyników. Uwaga – wyszukiwarka obsługuje do trzydziestu dwóch słów, więc dobierz charakterystyczne, krótsze zdania. Jeśli chcesz mieć stuprocentową pewność, że zostanie wyszukany identyczny content, wówczas cały cytat weź w cudzysłów, na przykład:
„to jest przykładowy tekst. Ma za zdanie sprawdzenie, czy treść się nie powiela”.
W wynikach wyszukiwania zostaną wyświetlone zaindeksowane przez Google strony, które mają dokładnie taką samą treść. Jeśli nie zostaną znalezione żadne witryny – świetnie, tekst nie został nigdzie zduplikowany. Ale powinien istnieć przynajmniej jeden wynik wyszukiwania – przecież wyszukiwarka zaindeksuje także Twoją stronę.
No właśnie. Co robić, gdy ma się duży serwis, a w nim mnóstwo podstron i chce się sprawdzić, czy na przykład opisy na nich się nie duplikują? W tym przypadku również wklej w wyszukiwarkę przykładową treść w cudzysłowach, ale poprzedź ją prefixem „nazwastrony.pl”.
Czyli będzie to wyglądać tak:
webiso.pl „to jest przykładowy tekst. Ma za zdanie sprawdzenie, czy treść się nie powiela”
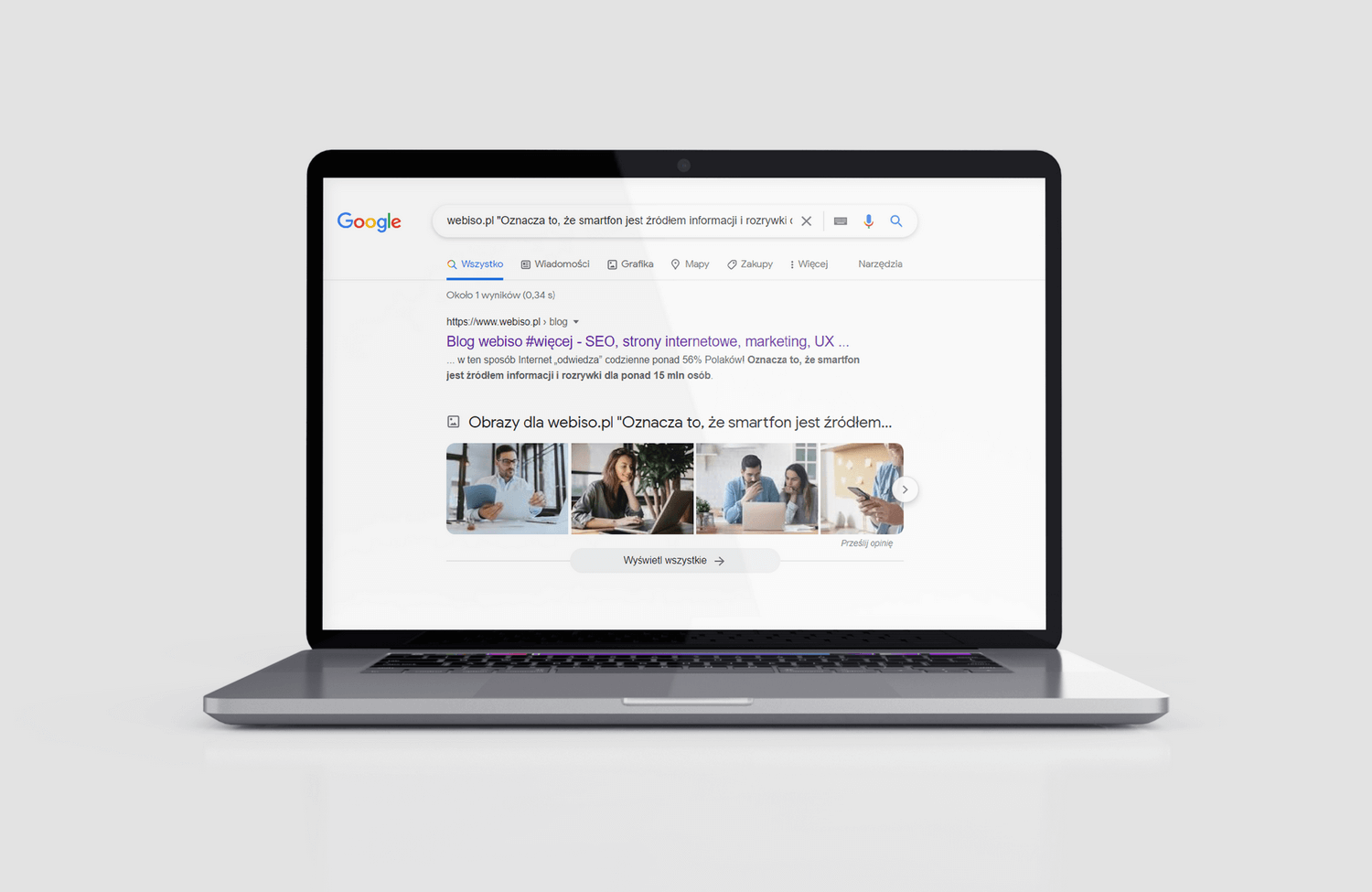
Sprawdzanie za pomocą wyszukiwania w Google, czy nasza treść nie została zduplikowana.
Jeśli jednak chcesz mieć szerszy ogląd, wówczas możesz skorzystać ze specjalistycznych serwisów analizujących treści. Tych jest w chwili obecnej kilkadziesiąt, znajdziesz je zaś, wpisując do wyszukiwarki duplicate content checker lub po polsku – narzędzia do sprawdzania powielonych treści.
Poszczególne narzędzia różnią się wyglądem oraz interfejsem, jednak ich zasadniczy cel jest zawsze taki sam – poddają analizie tekst (w tym celu wystarczy wkleić adres strony lub podstrony), a następnie pokazują rzetelne wyniki badania. W zależności od narzędzia możesz mieć do czynienia z kilkoma trybami analizy czy też możliwością przesłania pliku tekstowego. Pokazują one także porównania z innymi witrynami oraz procentowe podobieństwo z treściami na innych stronach.
Dzięki tak szerokiemu wyborowi serwisów z pewnością znajdziesz narzędzie, które najlepiej wpasuje się w Twój gust oraz da Ci dokładnie te informacje, których poszukujesz. Tutaj rodzi się oczywiście pytanie: co po otrzymaniu wyników? Jak je traktować? Jeśli mamy do czynienia z duplicate content, będziesz wiedzieć, co poprawić oraz jakie fragmenty tekstu zasługują na szczególną uwagę (czyli – które elementy powtarzane są najczęściej). Taka wiedza jest dobrym punktem wyjściowym do dalszych działań.
Duplicate content na mojej stronie – co robić?
Odpowiedź na takie pytanie nasunie się sama, jeśli pamiętasz podstawową zasadę Google, które zachęca do tworzenia oryginalnych, autorskich treści. I to właśnie one są przede wszystkim promowane oraz mogą liczyć na wysokie pozycje na listach wyszukiwania. Dlatego podstawowym działaniem, jakie należy podjąć do wykryciu powielonej treści, jest jej zmiana. Wspomniano wcześniej o opisach produktów w sklepie i ich różnych wersjach kolorystycznych. Jeśli chcesz mieć dobre pozycje, nie możesz „iść na łatwiznę” – każdy produkt musi mieć swój oryginalny opis. A jeśli opisy pochodzą ze strony producenta, wówczas należy po prostu przepisać je od nowa.
To nie tylko najprostsza metoda na to, aby skutecznie wyeliminować powielane treści, ale również doskonała okazja na działania SEO. Jeśli w nowym contencie użyjesz odpowiednich słów kluczowych, wówczas powinno to przynieść za jakiś czas rezultaty w postaci lepszego wypozycjonowania strony na te frazy. Jeśli nie masz pomysłu na to, jak zmienić istniejące treści, wówczas z pewnością pomoże Ci copywriter. Sprawy techniczne musisz powierzyć natomiast administratorowi strony.
O jakich sprawach technicznych mowa? Mamy tu na myśli wymienione wcześniej elementy, czyli np. brak przekierowania 301, pominięcie tagu noindex itp. Blokować duplikaty można również za pomocą robots.txt lub tagu meta robots. Jeśli z tych czy innych powodów ich zastosowanie nie jest możliwe, możesz „poinformować” Google o tym, która treść jest oryginalna, stosując wspomniany uprzednio link kanoniczny. To powinno skutecznie załatwić sprawę, jednak pamiętaj, że zawsze na pierwszej pozycji będą oryginalne treści.

Co robić, gdy ktoś kradnie Twoje treści?
Co zrobić w sytuacji, gdy jakaś witryna w sieci skopiowała Twoje oryginalne treści? Jeśli zrobiono to bez porozumienia, wówczas po prostu skontaktuj się z adminem tamtej witryny i zażądaj ich usunięcia. Jeśli to nie pomoże, możesz wówczas zgłosić plagiat do Google. W tym celu prześlij prośbę na mocy ustawy Digital Millennium Copyright Act. Gigant branży IT powinien zweryfikować zgłoszenie i po przyznaniu Ci racji strona z duplikatem zostanie wykluczona z indeksowania. Jeśli tak się nie stanie, można spróbować skonsultować sprawę np. z prawnikiem. Często już samo poinformowanie o takim zamiarze osoby przywłaszczającej sobie tekst przynosi oczekiwany skutek, skutecznie zniechęcając ją do wykorzystywania nieswoich treści.
Można także spróbować zabezpieczeń antykradzieżowych. Wiele stron stosuje w tym celu blokadę możliwości kopiowania elementów witryny. Inne rozwiązanie to automatyczne dodawanie linku do strony, z której dany fragment tekstu został skopiowany, jednak jest to znacznie mniej skuteczne, gdyż link można po prostu ręcznie usunąć. Dlatego kolejność działań w przypadku kradzieży treści powinna być następująca: zgłoszenie sprawy do admina strony, jeśli nie da to efektów – poinformowanie Google. Do innych sposobów powinniśmy się uciekać tylko jeśli poprzednie nie przyniosą skutków.
Podsumowanie – duplicate content szkodzi
Powielane treści mają bardzo negatywne oddziaływanie na pozycjonowanie strony oraz jej postrzeganie przez wyszukiwarki – nie tylko Google, ale również Bing, DuckDuckGo czy Yahoo. Dlatego za wszelką cenę należy unikać takich sytuacji i jeśli wykryje się duplicate content na swojej stronie, należy jak najszybciej to zmienić. Jak pokazaliśmy w powyższych przykładach, nie jest to szczególnie trudne, należy jedynie poświęcić sprawie nieco czasu. Nie można zapominać także o tym, że pomożesz w ten sposób swojej witrynie w osiągnięciu lepszego miejsca na liście wyników wyszukiwania.
Jak sprawdzać, czy treści się nie duplikują? Jeśli samodzielnie pisujesz treści na swoją stronę, nie będzie to potrzebne – wiesz przecież, że nie kopiujesz tekstów innych. Jednak w sytuacji, gdy masz duży serwis, a do pisania zatrudniasz osoby z zewnątrz, warto raz w tygodniu sprawdzić, czy ktoś przypadkiem nie „ułatwił sobie pracy” i nie dokonał plagiatu. Dzięki darmowym narzędziom będzie to proces szybki i, co istotne, bezpłatny – w łatwy sposób możesz więc uniknąć zjawiska kopiowania treści.

